Understanding-Based AGI: A Framework for Genuine Machine Intelligence
What if the path to artificial general intelligence isn’t about bigger models, but about understanding how understanding actually works?

The Starting Point
I’ve spent over 30 years as a technologist. Over the last year, like a lot of people in tech, I’ve watched the AI revolution unfold with a mix of genuine excitement and a nagging sense that something fundamental is being overlooked. The capabilities are extraordinary, no question. We could easily spend one to two decades realizing the potential of what we have right now, even if nothing advanced further. But the more I worked with these systems, the more I kept bumping into the same gap: they can produce remarkable outputs, but they lack the structural capacity to truly comprehend, to maintain coherent understanding across contexts, to know what they know and what they don’t.
That observation isn’t a criticism. It’s a starting point. I realized my own learning process, the way I naturally acquire and integrate knowledge, was fundamentally different from how AI systems learn. Not better in some abstract sense, just structurally different in ways that seemed important. So I started writing it down.
What began as notes on my own learning style evolved into something bigger: a theoretical framework for what genuine machine intelligence might require. I didn’t set out to build a grand theory. I set out to articulate something I could see clearly but couldn’t find anyone describing the way I experienced it. The framework grew from there, and it’s still growing. What you’re reading here is a snapshot, not a finished product. I’m still working through consistency, making sure every piece explains itself well enough and connects to the others coherently. But it’s far enough along to be worth sharing. The timing of this release is worth a brief mention: recent developments around Yann LeCun’s work and the direction of AMI caused me to think more carefully about where my own research sits in the broader landscape, and pushed me to put this out now rather than continue refining in private.
I want to be honest about the scope of that starting point. My own experience of learning was the initial spark, but the framework itself is informed by a broader exploration of how human intelligence and learning work in general. That said, people learn differently, and those differences aren’t reducible to a handful of neat categories. This is one direction that makes sense to me, grounded in my own experience but reaching well beyond it into how cognition works more broadly. Someone starting from a different perspective might build something very different, and it could be equally valid.
I should be upfront about something: I’m not a credentialed AI researcher. I don’t have a PhD in machine learning or cognitive science. What I do have is decades of experience building complex systems, a deep curiosity about how understanding actually works, and the discipline to follow an idea honestly even when it leads into unfamiliar territory. A researcher with deep background in knowledge representation might look at parts of this framework and recognize things that are well-established emergent properties of simpler systems. That’s fine. Whether these ideas hold up is something the work itself will have to demonstrate.
Equally important: this framework was developed mostly in isolation. I didn’t read papers, survey the literature, or try to bone up on existing approaches. That wasn’t laziness or oversight; it was a deliberate choice. Formulating ideas without steeping yourself in established methodology preserves the ability to arrive at conclusions independently. Any convergence with existing work is genuine rather than absorbed, and any divergence might be where the interesting contributions live. The isolation is a phase, not a permanent state, and engaging the literature honestly is next.
One more thing worth saying clearly, because it shapes everything that follows: the human mind is the starting point here, not the destination. We start from human cognition because it’s the best model we have of advanced learning, reasoning, and creativity. But the goal is not to build an electronic replica of a human brain. The analogy to robotics is direct: humanoid robots make sense for specific reasons, navigating human spaces, using human tools. But a warehouse robot doesn’t need legs and a surgical robot doesn’t need a face. As this work moves toward anything practical, I need to be ready to let any amount of it go. Not because the ideas were wrong, but because the practical space of implementation will reveal its own logic. What matters is finding what actually works: existing technology, new technology, patterns from nature, novel computational primitives that nobody has tried because the field has been building on the same basic artificial neuron for decades. The foundation is a starting point, not a permanent constraint.
The Core Idea
Current AI systems, including the most capable large language models, are trained primarily through next-token prediction on enormous text corpora, adjusting billions of weights to become increasingly accurate at predicting what comes next. The results are genuinely remarkable. The models themselves, their post-training, the tooling they’re built into, it’s a whole ecosystem that just keeps evolving, and the results keep getting more extraordinary. But there’s a fundamental difference between prediction, even extraordinarily good prediction, and understanding what those predictions mean.
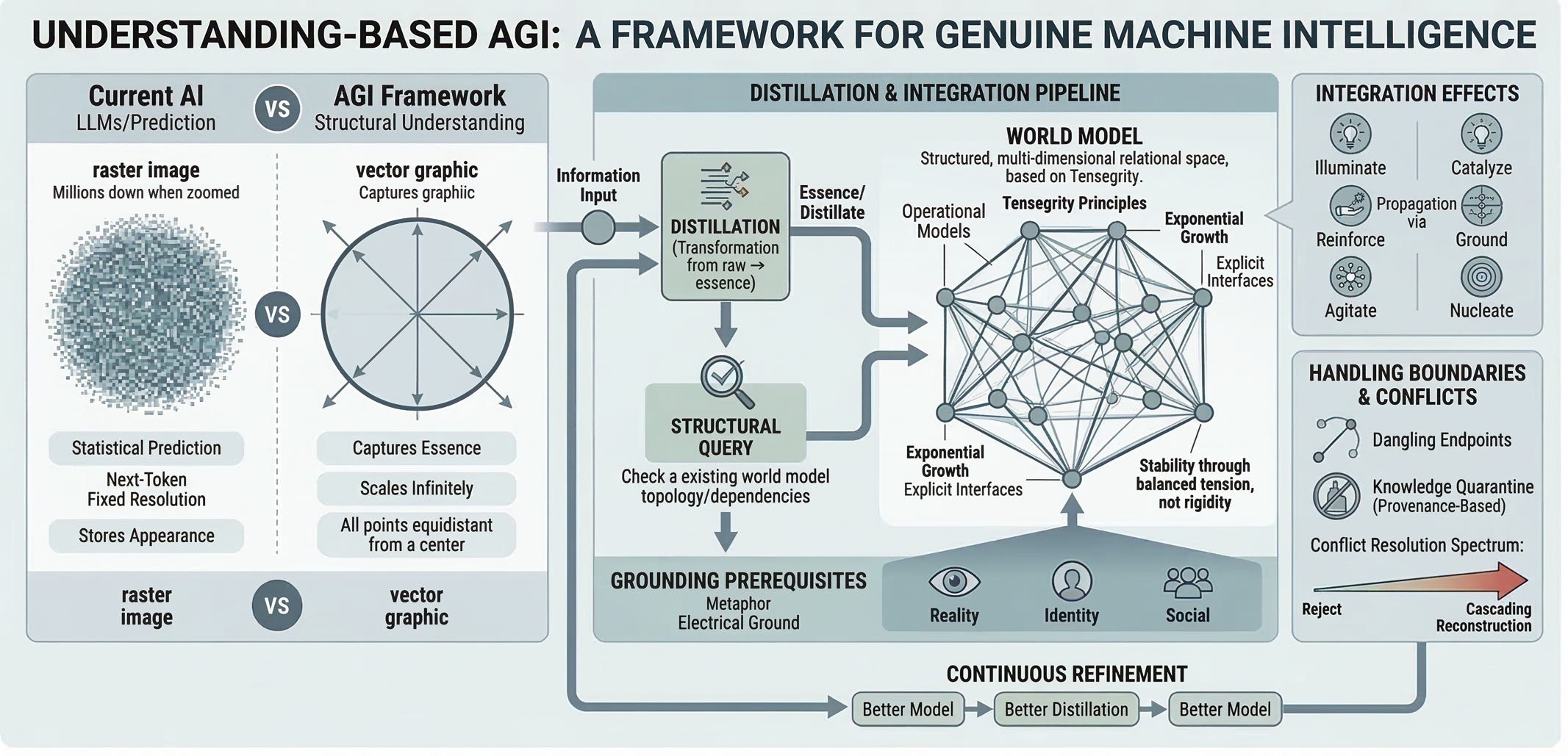
Think of it this way: current AI stores knowledge like a raster image, millions of pixels that capture the appearance of something at a fixed resolution. Understanding is like a vector graphic, mathematical relationships that capture the structural essence. The raster stores what a circle looks like. The vector stores what a circle is: all points equidistant from a center. One breaks down when you zoom in. The other scales infinitely because it captured the actual thing, not just its appearance.
Current models have been trained on so much data, and gotten so good at predicting what comes next, that their outputs can look remarkably like understanding. But underneath, it’s still statistical associations across billions of weights, not structures that represent what something actually is.
Specifically, these systems lack explicit knowledge structures that can be inspected and queried, mechanisms for detecting and resolving contradictions, the ability to distinguish “knowing that” from “knowing why,” and resistance to catastrophic forgetting during continuous learning.
This framework proposes that genuine understanding requires something specific: the active extraction of essence from information and its structural integration into a persistent, coherent model of the world.
I call this process distillation, and it is the core mechanism of the framework. Not compression, not memorization, but an irreversible transformation that produces something new. The way distilling a spirit extracts essence from raw ingredients and produces something that cannot be reversed back into grain. The critical point is that distillation is about identifying essence, not necessarily achieving reduction. Sometimes the essence of something is a tiny fraction of the source material. Sometimes the entire source is essential and nothing can be removed without loss. Both are valid outcomes of the same process.
And distillation isn’t bound to formal learning contexts. It happens during any activity, under any circumstance. You might be in the middle of solving a problem and make a small discovery: a trick for doing something more efficiently, a previously unknown property of the material you’re working with. Learning is a constant background process, not something that only happens when you sit down to study.
The Architecture of Understanding
If distillation is how knowledge gets extracted, then the world model is where it lives. The framework proposes that knowledge exists not as a flat database of facts or as distributed weights in a neural network, but as a structured, multi-dimensional relational space. Think of it as a tensegrity structure: a system that achieves stability through balanced tensions rather than rigid connections. Strength emerges from relationships between elements, not from the elements themselves. The structure can flex, reorganize, and grow while maintaining coherence.
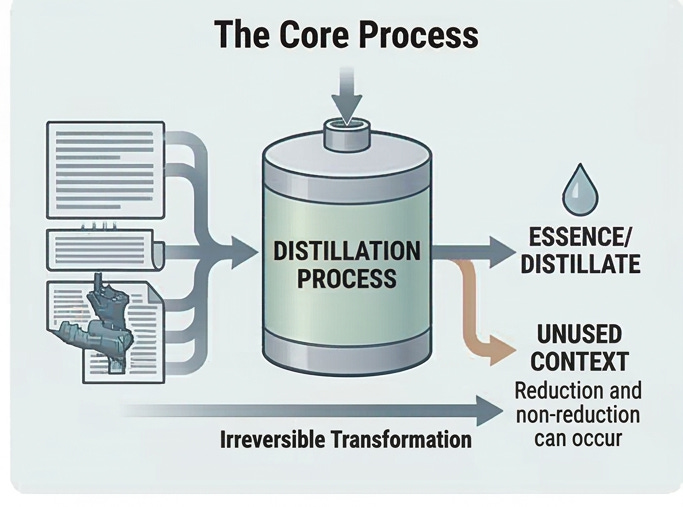
Every node in this space represents an operational understanding, not a fact but a working model of how something behaves. These connect to other models through explicit interfaces. The same sub-model, something like “exponential growth,” can appear embedded in biology, economics, physics, and technology contexts. That’s not redundancy; it’s the same understanding accessible through multiple connection paths.
How New Knowledge Enters
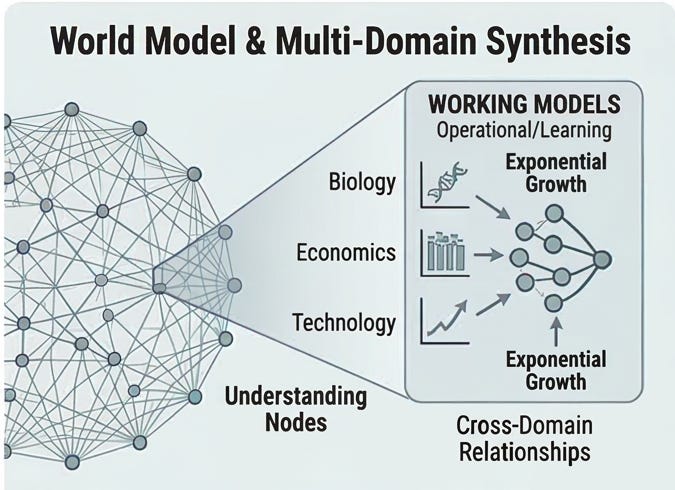
When new information arrives, it passes through what I call the integration pipeline. First, the information gets distilled: its essence is extracted, its interfaces are identified. Then the existing world model is queried, not through similarity search or pattern matching, but through structural query, examining the actual topology and dependencies of what you already know.
Based on that query, incoming knowledge falls into one of four categories:
Confirmatory fits naturally into existing structure, filling gaps and adding detail. It integrates straightforwardly.
Extending is compatible but adds new dimensions, connecting previously unconnected models. It expands the structure.
Dissonant contradicts existing models, creating tension that needs resolution. It triggers a conflict resolution process.
Alien has no connection points at all; it’s fundamentally novel, with no analog in your current understanding. It gets held in its strangeness, preserved with dangling endpoints rather than forced into familiar categories.
But classification only describes what the knowledge is relative to your model. A complementary question is what does the knowledge do when it arrives?
Integration Effects
The interaction between a distillate and the world model produces one of six primary effects:
Illuminate reveals connections already present but invisible; this is the “aha” moment of understanding something you technically already knew.
Catalyze triggers a reorganization that was latent, where the conditions were already present but needed a spark.
Reinforce strengthens existing structure without revealing anything new.
Ground anchors abstract knowledge to reality, connecting the symbol to the referent.
Agitate creates productive tension, signaling that the model needs work.
Nucleate seeds entirely new understanding where none existed, becoming a point around which future knowledge can organize.
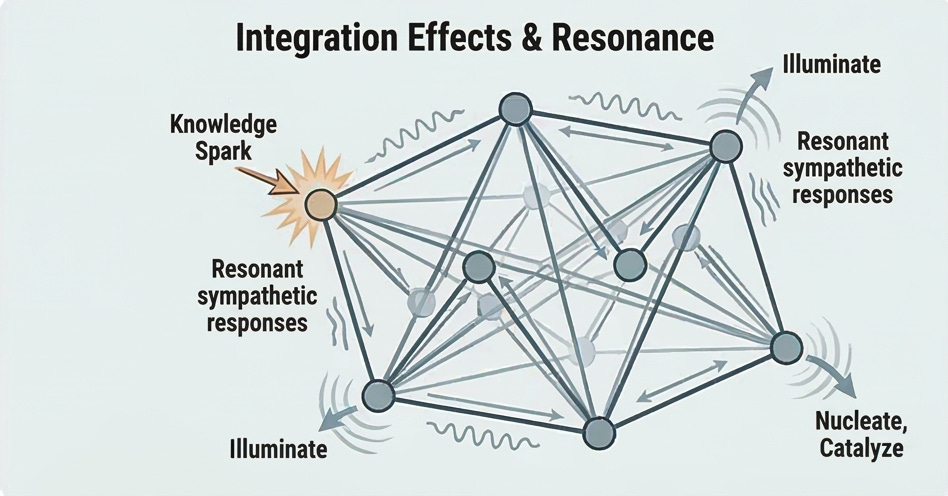
The effect is a property of the interaction, not solely of the knowledge itself. The same piece of knowledge might illuminate one model and nucleate in another, depending on what’s already there. And the initial effect propagates through the model’s topology via resonance: one strike producing sympathetic responses that travel along structural connections, potentially triggering secondary effects of different types at distant nodes. This is the mechanism behind the common experience of learning one thing and suddenly having several other things click into place.
What We Don’t Know (And Why That Matters)
Two mechanisms handle the boundaries of understanding.
Dangling endpoints are the framework’s way of preserving incomplete knowledge as a first-class entity. When you encounter something genuinely alien, a concept with no analog in your existing understanding, the worst thing you can do is force it into a familiar category. Instead, you hold it in its strangeness, maintain its interfaces, and wait for the connections to reveal themselves. In the late 1500s, Tycho Brahe spent decades faithfully recording planetary observations that didn’t fit existing models. Kepler later found precise mathematical laws in that data, but couldn’t explain why planets behaved that way. Nearly a century later, Newton’s law of universal gravitation provided the answer, and decades of honestly preserved observations snapped into place. That’s what happens when a system resists the temptation to force or discard what it doesn’t yet understand.
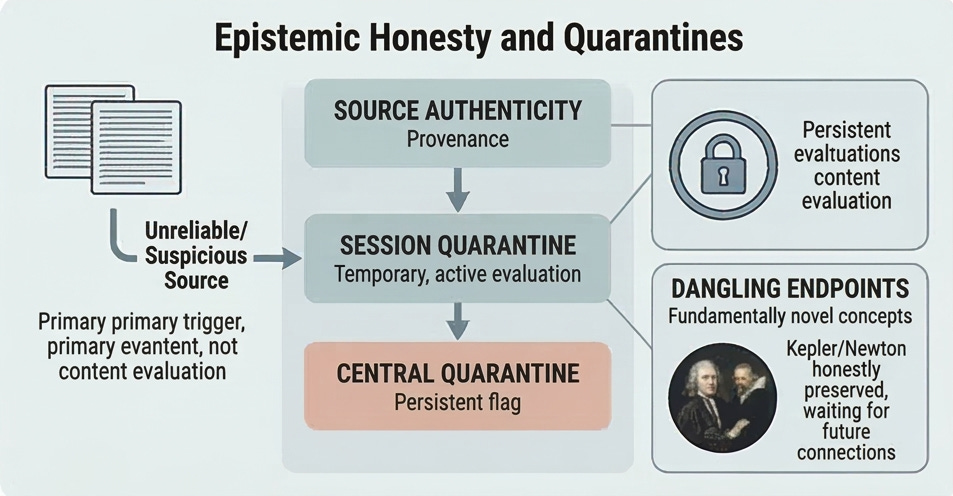
Knowledge quarantine handles uncertainty about reliability rather than meaning. A critical insight here: quarantine should be triggered by provenance before content evaluation. Sophisticated misinformation can appear perfectly coherent, so the source matters as much as the substance. The framework uses a two-tier system: session-level quarantine for information being actively evaluated, and central quarantine for material that’s been flagged but not yet resolved. A tenured professor lecturing in their field gets different treatment than an anonymous social media claim, regardless of how plausible either sounds. This is epistemic honesty built into the architecture, and it extends to defending against distributed poisoning, where multiple benign-seeming pieces from different sources are designed to combine into false beliefs. Each piece passes individual validation, but the composite picture is deliberately misleading.
Conflict Resolution
When new knowledge contradicts existing understanding, the system needs a principled way to handle it. The resolution depends on evidence quality, how central the challenged concept is, and what would cascade if the model changed.
The options range from rejecting weak evidence, to local modification of peripheral concepts, to quarantining credible-but-insufficient evidence for later resolution, to accumulating tension when the evidence is mixed. At the extreme end, strong evidence against a central concept triggers cascading reconstruction: systematically rebuilding affected models, updating connections, and verifying coherence at each step.
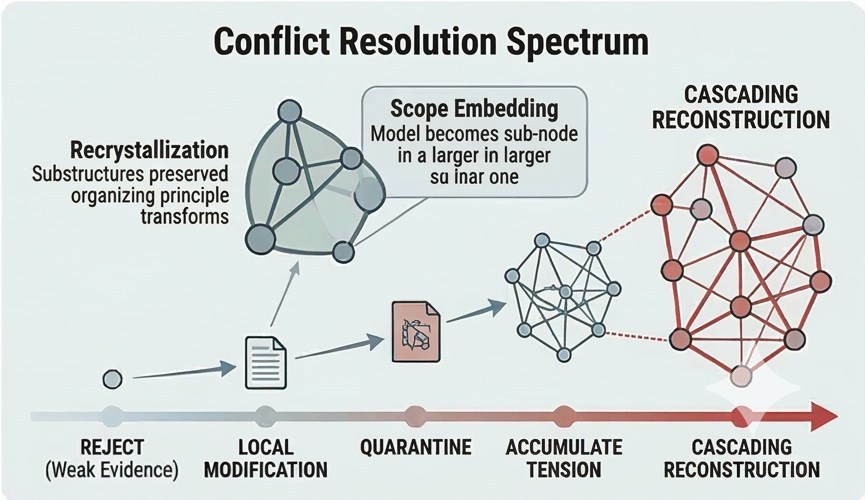
Sometimes a small piece of information in the right structural position triggers massive reorganization. The framework calls this recrystallization: the substructures are preserved, but the organizing principle transforms. Imagine learning with certainty that Earth is part of an alien experiment. All your observations remain valid, all local models still work, but the meta-context shifts entirely. Everything gets recontextualized. A related challenge is scope embedding, where your existing model turns out to be one node in a vastly larger structure, like someone who has a complete model of a single room stepping outside for the first time.
The Ground Beneath
All of the above depends on a prerequisite that’s easy to overlook: grounding, the mechanism by which abstract representations connect to the things they represent.
Think of an electrical circuit: every circuit requires a ground, a common reference potential from which all other voltages are measured. Without ground, voltages float unpredictably and the circuit has no stable reference. Similarly, knowledge without grounding has no stable reference to reality. It may be internally consistent but disconnected from what it purports to represent.
Grounding operates at three levels:
Reality grounding connects abstract knowledge to the actual structure of the physical world; this is the most concrete level and arguably the most tractable for AI work.
Identity grounding provides a persistent operational frame of reference: the system’s awareness of its own state, capabilities, and boundaries.
Social grounding provides understanding through interaction with other agents, building on reality and identity grounding.
For embodied intelligences like humans, grounding emerges naturally through sensorimotor experience. For disembodied systems, grounding is the fundamental challenge, arguably the central problem for achieving genuine artificial intelligence. In practice, grounding likely spans a spectrum: simulated environments can provide structured grounding during training, passive real-world access through sensors and data feeds gives ongoing connection to reality, and full embodiment provides the richest grounding of all. These approaches aren’t mutually exclusive. This framework doesn’t pretend to have solved the grounding problem. But it names it explicitly and treats it as a foundational requirement rather than an afterthought.
Continuous Refinement
Understanding isn’t static. Your ability to distill is bounded by your model’s maturity. Early distillations may be inadequate, not from carelessness, but from insufficient conceptual foundation at the time of first encounter.
This is why re-distillation matters. As the world model grows, earlier distillations can be revisited with deeper context. Reading the same book at 20 and at 40 yields different insights; the material didn’t change, but your capacity to extract essence matured. This creates a positive feedback loop: better model enables better distillation, which enables a better model.
The framework also distinguishes between the world model, the persistent and comprehensive representation of all accumulated understanding, and working models, which are distilled out of the world model for specific contexts. That generation process is itself a form of distillation: extracting what’s relevant from a vast structure and producing something smaller and usable. Working models come in two varieties: operational ones (stable, efficient, discarded when done) and learning ones (living, expanding, restructuring as understanding deepens). In humans, this assembly is instinctual; you walk into a class, spend a few minutes ramping up, and the relevant pieces pull themselves together.
Something interesting happens during working model assembly: when you pull pieces from multiple distant areas of the world model into a smaller, focused context, relationships that span the full breadth of your understanding become visible in a way they weren’t before. Things that are structurally far apart suddenly reveal their connections when placed side by side. Insights from working models flow back through the integration pipeline.
Functional Skills
The framework has focused so far on knowledge acquisition, but there’s another dimension: operational capabilities, how to actually use knowledge. Reasoning methodologies, problem-solving strategies, techniques and procedures, and understanding when and how to apply each approach. Critically, these functional skills should be learned through the same distillation and integration process as any other knowledge, not hard-coded as external frameworks. A truly intelligent system doesn’t just store what it knows; it stores how to apply what it knows, and that toolbox is distilled, integrated, and refined through experience like everything else.
What This Framework Is and Isn’t
Let me be clear about what I’m proposing and what I’m not.
This framework claims:
Understanding is structurally different from pattern matching and requires different mechanisms
Knowledge integration must be structural, maintaining explicit relationships and dependencies
Grounding, the connection between symbols and what they represent, is a foundational requirement
Conflict resolution must be explicit, not implicit; the system should know when it’s confused
Coherence, not accuracy on benchmarks, is the organizing principle of genuine understanding
A system built on these principles would be fundamentally different in architecture from current LLMs
The integrity of the knowledge base must be actively defended through principled validation and quarantine
This framework does not claim:
To have a complete implementation; this remains theoretical
To have solved the grounding problem, which may be the hardest open question in AI
That current AI systems are useless or that pattern matching isn’t valuable
That consciousness is required for understanding (the framework is agnostic on this)
That the goal is to replicate a human mind; human cognition is the starting point, not the destination, and implementation should embrace whatever actually works
That this approach will definitely work; it’s a set of hypotheses that need testing
An important acknowledgment: this document deliberately over-specifies, identifying and reasoning through every concept and mechanism I can perceive. In practice, many of the things described here may turn out to be natural emergent properties of a working system rather than components that need to be explicitly built. The transition from theory to anything practical will almost certainly involve dramatic simplification. The value is in having thought it all through, not in assuming every piece will be literally constructed as described. And to be clear: even the thinking-through isn’t finished. This represents where the framework is now, not where it ends up.
The Path Forward
The work ahead follows a natural progression, where each phase has value independent of whether the next one happens.
Continued refinement comes first: sharpening definitions, filling gaps, stress-testing the internal logic. Every pass reveals assumptions that need to be explicit and edge cases that expose where the theory is weakest.
Engaging the literature follows. Not to seek validation, but to seek information: understanding what’s been tried, what’s been proven, what’s been abandoned and why. The framework’s core hypotheses should survive contact with existing research, be refined by it, or be honestly set aside if the evidence warrants.
Technology exploration and experimentation run in parallel. On one track: identifying computational primitives that could serve structural integration, explicit conflict resolution, and coherence maintenance, looking beyond conventional neural network architectures and actively searching for novel approaches wherever they can be found, whether in nature, in mathematics, or in domains no one has thought to borrow from yet. On the other: isolating individual mechanisms from the framework and testing them independently. Can you build a small system that does genuine structural integration? Can you demonstrate re-distillation improving model quality over successive passes? Each experiment either opens a door or closes one.
Implementation, if the evidence supports it. The working assumption is that a system built on structural understanding would be fundamentally different in scale from current LLMs: smaller, more efficient, more interpretable. If that holds, meaningful work can begin on modest hardware.
Every phase produces something of value regardless of what comes next. The theoretical framework contributes ideas worth engaging with. The experiments produce knowledge. There is no scenario in which this work is wasted. At any point, the honest conclusion might be that the path has reached a dead end, or that the work finds its best use as a contribution to someone else’s research. Those are legitimate outcomes. The only outcome that would represent failure is dishonesty: forcing results, misrepresenting progress, or continuing past the point where the evidence justifies it. And at every step, the willingness to let go of what doesn’t survive contact with reality is not a weakness of the framework; it might be its most important feature.
An Invitation
This article is a first introduction, not the complete picture. I’ve put together a research page with more detail on the core concepts, an interactive navigator for exploring the framework’s structure, and a concept atlas for quick reference. It’s at inlookingout.com/portfolio/research. The full repo will follow once it’s cleaned up and further along, but there’s enough there to go deeper if you want to.
If any of this resonates, if you see connections to your own work or have critiques that could make it better, I’d welcome the conversation. And if you’ve experienced that moment where learning something new causes several other things to click into place, you’ve already felt what this framework is trying to describe. The question is whether we can build machines that do it too.